Editing Data

There's some string and numeric data down at the bottom of the file. The final string appears to be multiple strings stuck together. (You may need to increase the width of the Operand column to see the whole thing.) Notice that the opcode for the very last line is '+', which means the operand is a continuation of the previous line. Long data items can span multiple lines, split every 64 characters (including delimiters), but they are still single items: selecting any part selects the whole.
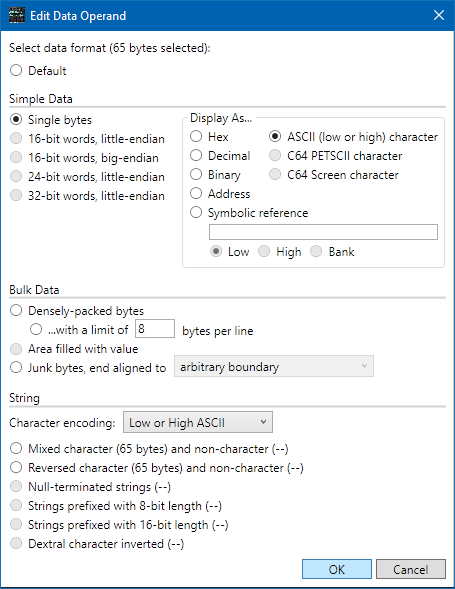
Select the last line of data in the file ($2030), then Actions > Edit Operand. You'll notice that this dialog is much different from the one you got when editing the operand of an instruction. At the top it will say "65 bytes selected". You can format this as a single 65-byte string, as 65 individual items, or various things in between. For now, select Single bytes, and then on the right, select ASCII (low or high) character. Click OK.

Each character is now on its own line. The selection still spans the same set of addresses.
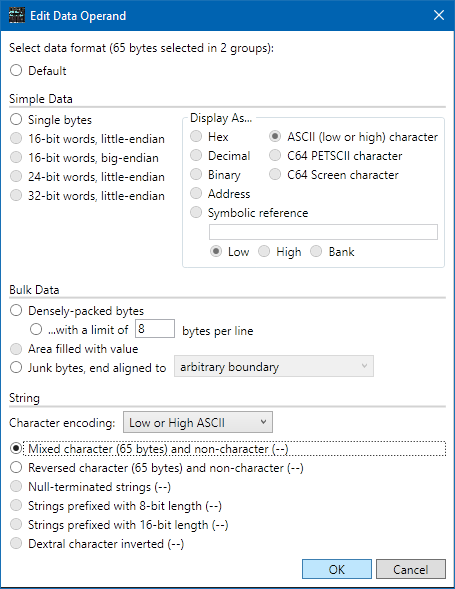
Select address $203D on its own, then Actions > Edit Label. Set the label to "STR1". Move up a bit and select address $2030, then scroll to the bottom and shift-click address $2070. Select Actions > Edit Operand. At the top it should now say, "65 bytes selected in 2 groups". There are two groups because the presence of a label split the data into two separate regions. From the Character encoding pop-up down in the "String" section, make sure Low or High ASCII encoding is selected, then select the Mixed character and non-character string type and click OK.

We now have two .STR lines, one for "string zero ",
and one with the "STR1" label and the rest of the string data.
This is okay,
but it's not really what we want. The code at $200B appears to be loading
a 16-bit address from data at $2025, so we want to use that if we can.
Select Edit > Undo three times. You should be back to the
state where there's a single .STR line at the bottom of
the file, split across two lines with a '+'.
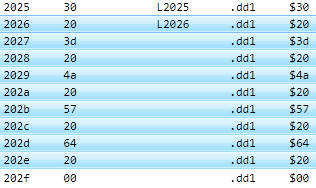
Select the line at $2026. This is currently formatted as a string, but that appears to be incorrect, so let's format it as individual bytes instead. There's an easy way to do that: use Actions > Toggle Single-Byte Format (or hit Ctrl+B).
The data starting at $2025 appears to be 16-bit little-endian addresses that point into the table of strings, so let's format them appropriately.
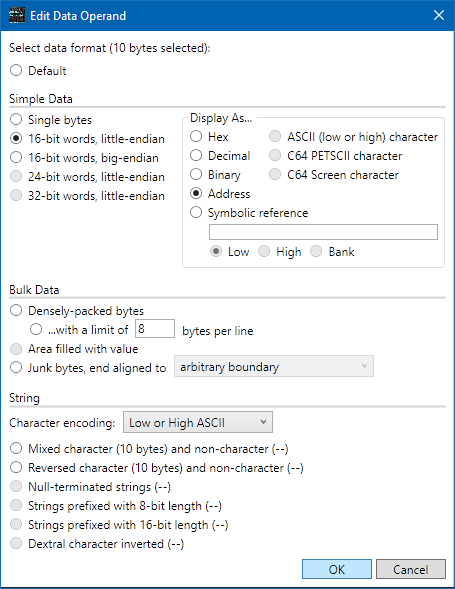
Select the line at $2025, then shift-click the line at $202E. Right-click and select Edit Operand. If you selected the correct set of bytes, the top line in the dialog should now say, "10 bytes selected". Because 10 is a multiple of two, the 16-bit formats are enabled. It's not a multiple of 3 or 4, so the 24-bit and 32-bit options are not enabled. Click the 16-bit words, little-endian radio button, then over to the right, click the Address radio button. Click OK.
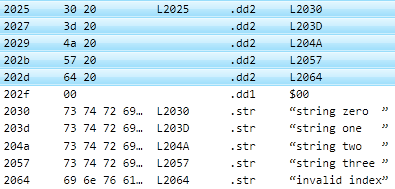
We just told SourceGen that those 10 bytes are actually five 16-bit numeric
references. SourceGen determined that the addresses are contained in the
file, and generated labels for each of them. Labels only work if they're
on their own line, so the long string was automatically split into five
separate .STR statements.
Note we didn't explicitly format the string data. We formatted the addresses at $2025, which placed labels at the start of the strings, but the strings themselves were automatically detected and formatted by SourceGen. By default, SourceGen looks for ASCII strings, but this can be changed in the project properties. You can even disable the string auto-detection entirely if you want.